
How to Reduce DevOps Pipeline Bottlenecks
DevOps pipelines often slow down due to common bottlenecks like manual approvals, resource constraints, and flaky tests. These delays can cost teams significant time and money, with some reporting losses nearing seven figures annually.
To address these challenges, AI-powered tools like Kanu AI offer solutions by:
- Predicting pipeline issues: Machine learning analyzes historical data to forecast potential delays.
- Streamlining testing: Automated validation focuses on relevant tests, cutting testing time from 28 minutes to 90 seconds.
- Improving deployments: AI-generated infrastructure code reduces configuration errors by up to 85%.
- Self-healing automation: Automatically resolves issues, saving up to 80% of debugging time.
Kanu AI's features, such as predictive analytics, root cause analysis, and dynamic resource allocation, enable teams to deploy faster, reduce errors, and improve efficiency. This shift from reactive to proactive problem-solving helps teams focus on delivering quality code instead of troubleshooting.
What Causes CI/CD Pipeline Bottlenecks And How To Fix Them? - Next LVL Programming
Finding Bottlenecks with Kanu AI Predictive Analytics

Kanu AI leverages predictive analytics to scan logs, metrics, and historical data, helping you anticipate pipeline issues before they cause delays. Its machine learning models - covering supervised, unsupervised, and reinforcement learning - analyze past builds, test results, incidents, and performance metrics to forecast potential problems. This allows you to tackle issues like resource contention, flaky tests, or configuration drift early, reducing disruptions in production.
With an accuracy rate of 87%, Kanu AI identifies slowdown points by analyzing metadata and performance data. Its natural language processing (NLP) capabilities dig into logs, tickets, and commit messages to uncover inefficiencies that might otherwise go unnoticed. When failures occur, the AI-powered Root Cause Analysis (RCA) tool quickly scans verbose logs and stack traces to pinpoint the exact files and lines of code responsible for the problem. Tasks that might take a platform engineer 15–30 minutes to resolve manually can be addressed in about 10 minutes with Kanu AI's assistance.
These insights clearly identify the pipeline phases where slowdowns happen, making it easier to implement targeted improvements.
Common Pipeline Bottlenecks
Pipeline slowdowns often fall into a few key categories. Build delays happen when pipelines include redundant steps or run out of resource quotas during parallel job execution. Test failures, especially flaky tests, lead to repeated pipeline reruns, wasting both time and resources. Resource contention arises when too many jobs compete for limited infrastructure, exhausting quotas. Deployment risks stem from issues like infrastructure drift, where mismatched Terraform states or outdated merge request branches cause last-minute failures.
Predictive analytics tackles these bottlenecks by identifying phases that frequently slow down, require manual intervention, or face resource constraints. For instance, in May 2025, a financial SaaS platform dealing with a 30% deployment failure rate due to flaky database tests and registry downtime adopted autonomous self-healing. The results were dramatic: pipeline reruns dropped by 65%, mean time to repair (MTTR) went from 45 minutes to under 10 minutes, and the team doubled their shipping frequency.
Addressing these bottlenecks lays the groundwork for AI-driven solutions that simplify and enhance your DevOps processes.
Using Kanu AI's Intent and DevOps Agents
Kanu AI's Intent Agent translates natural language objectives into actionable CI/CD configurations, while the DevOps Agent examines code, stack traces, and configuration files to pinpoint issues quickly. These agents connect telemetry, code, and deployment data to map relationships across multi-cloud and hybrid environments.
Operating in a read-only mode, the agents generate structured reports that detail root causes, affected files, and suggested fixes. By continuously feeding telemetry and outcome data back into the AI models after each release, Kanu AI adapts to your evolving infrastructure and codebase. This approach helps prevent the "concept drift" that often reduces the accuracy of traditional monitoring tools over time.
Faster Testing with Kanu AI Validation Checks
Testing delays can be a major drain on resources and a roadblock to timely releases. Kanu AI addresses this challenge by running over 250 automated validation checks across live systems, including UI, APIs, databases, and accessibility areas. Instead of executing the entire test suite for every update, the platform leverages predictive analytics to focus only on tests that are directly relevant to the changes made. This approach cuts testing time dramatically - what used to take 28 minutes can now be done in just 90 seconds - while also reducing resource consumption and avoiding release delays.
Kanu AI also simplifies handling production environments. It automatically manages popups and adjusts tests to fit live conditions, minimizing the need for manual adjustments. If a test fails, the system quickly pinpoints the issue and suggests fixes, significantly cutting down debugging time. This streamlined process not only speeds up testing but also ensures smoother troubleshooting later. As Atulpriya Sharma, Sr. Developer Advocate at Testkube, explains:
"The real bottleneck isn't running tests: it's analyzing failures, identifying root causes, and deciding what to fix first."
Automated Test Prioritization and Execution
Kanu AI's Intelligent Test Planner takes high-level objectives, like "verify add-to-cart functionality", and transforms them into actionable test steps automatically. It also allows step-level control, so you can decide whether a specific failure should stop the pipeline, continue running, or be skipped altogether. This prevents unnecessary interruptions in the testing process.
The platform integrates with HyperExecute to boost test execution speeds by up to 70%, running tests across more than 3,000 combinations of browsers, real devices, and operating systems. By prioritizing execution, Kanu AI ensures that testing focuses on critical areas, allowing teams to quickly identify and address anomalies.
Detecting Anomalies with AI-Powered QA
Kanu AI's Q/A Agent excels at identifying failures in real time and offers actionable suggestions to maintain testing reliability. It uses visual queries to check UI elements, ensuring proper image loading, consistent colors, and pixel-perfect accuracy. Its auto-healing feature dynamically updates test scripts to accommodate UI or code changes, reducing the occurrence of flaky tests.
The system's AI-driven root cause analysis is a game-changer, saving up to 80% of the time developers typically spend diagnosing errors. As Karan Ratra, Senior Engineering Leader at Walmart, notes:
"Generative and predictive AI can help segregate the errors based on issues rather than just printing them in the logs, and help us categorize them... saving up to 80% of developers' time in finding the actual root cause."
Teams that adopt AI-driven testing have reported 40% to 60% increases in deployment frequency, along with significant reductions in Mean Time to Recovery (MTTR). This combination of speed and precision makes Kanu AI a powerful tool for modern testing workflows.
Better Deployments with Intelligent Orchestration
Once testing is streamlined, deployment delays are the next hurdle. Often, these delays come from the tedious process of manually translating infrastructure requirements into code and fixing deployment failures. Enter Kanu AI, which acts as an AI Cloud Engineer. It handles both application and infrastructure changes at the same time, generating production-ready Terraform, AWS CDK, and CloudFormation code. This ensures your infrastructure stays in sync with evolving application needs, effectively avoiding configuration drift.
Automated Infrastructure Code Generation
Kanu AI simplifies deployment by generating infrastructure code alongside application updates, ensuring your stack remains consistent. Whether it’s Terraform, CDK, or CloudFormation, Kanu AI keeps everything aligned as requirements evolve. Its AI models boast over 90% accuracy, cutting development time by 60–70%. The platform is deployed as a single-tenant service within your VPC, integrating seamlessly with your existing identity, networking, and security controls while managing deployments. By leveraging context-aware infrastructure platforms like Kanu AI, configuration errors can drop by up to 85%.
Installation is straightforward - use the AWS Marketplace for a one-click CloudFormation setup. Once installed, Kanu immediately starts learning your team’s preferences based on past deployment decisions. This automated code generation not only accelerates deployment but also lays the groundwork for quick error resolution in future iterations.
Iterative Error Resolution and Deployment Readiness
Traditional pipelines often grind to a halt when deployments fail, leaving engineers to sift through logs and manually fix errors. Kanu AI addresses this "delivery gap" by analyzing real-time logs and metrics, automatically updating the infrastructure code, and retrying deployments until all validation checks are passed. The platform operates under a strict rule:
"No pull request is created until the system works in your environment" – getkanu.com.
Before a pull request reaches human review, Kanu runs over 250 automated validation checks against live systems, using real endpoints and data paths. This validation-first process delivers impressive results. AI-powered DevOps systems have been shown to reduce deployment failures by 67% and cut incident response times from hours to minutes.
For example, a SaaS team managing 35 microservices on AKS saw their deployment failure rate drop from 18% to 6% within four months. Their incident response time went from 4–8 hours to just 45 minutes, saving $420,000 annually. Kanu AI’s ability to catch subtle configuration errors during the planning phase provided instant root cause analysis, eliminating the need for time-consuming manual investigations.
sbb-itb-3b7b063
Monitoring and Iterating for Continuous Improvement
Deployment success isn't the end - it's the starting point for ongoing optimization. As systems scale, new bottlenecks emerge, dependencies shift, and services evolve. Staying ahead requires constant monitoring combined with automated iteration. Kanu AI embraces this feedback loop by analyzing real-time telemetry to detect inefficiencies and automatically addressing them through pull requests.
Using Log and Metric Analysis for Diagnostics
Traditional troubleshooting can be a time sink, with investigation and diagnosis often taking up more than 50% of the total time spent resolving an incident. Instead of manually piecing together fragmented logs and dashboards, Kanu AI correlates logs, traces, and metrics to deliver diagnostics in seconds - turning hours of detective work into precise, actionable insights.
Rather than generic error messages, Kanu AI provides context-aware diagnostics. For instance, it can identify specific issues like a missing database URL or a timeout with a third-party API [45,46]. This level of precision is vital, especially when downtime costs are so steep - 91% of mid-size and large enterprises report losses exceeding $300,000 per hour during outages, with nearly half facing costs over $1 million per hour.
Kanu AI also analyzes pipeline phases - like initialization, build, test, and deploy - to uncover hidden delays. For example, it might highlight slow Docker daemon validation or excessive image-pulling times, which occur before any code even executes. By isolating metrics like "build preparation" time, teams can identify inefficiencies that traditional monitoring tools might miss. Meta, for example, achieved a nearly 50% reduction in Mean Time to Resolution (MTTR) for critical alerts after deploying an internal AIOps platform across 300+ engineering teams.
These detailed diagnostics pave the way for proactive, automated fixes.
Continuous Tuning with Pull Requests
Kanu AI takes diagnostics a step further by automating the resolution process through pull requests. When it detects a familiar failure - like a configuration issue, resource limit problem, or missing dependency - it creates a new branch (e.g., selfheal-<git-sha>), applies the fix, validates the pipeline, and submits a pull request for review. This self-healing workflow often resolves issues before they even come to an engineer's attention.
The system doesn’t stop there. Developer feedback - whether approving or rejecting AI-generated pull requests - feeds back into the platform, helping it learn and adapt to team-specific workflows and preferences over time. This continuous learning ensures the AI becomes more accurate and aligned with team practices. In one case, a team using AI-assisted diagnostics slashed the time spent on investigation from 70% of total MTTR to just 11%.
"Self-healing CI pipelines aren't about replacing developers. They eliminate the repetitive, low-value work that slows teams down." – Semaphore
Traditional vs Kanu AI-Driven Pipelines
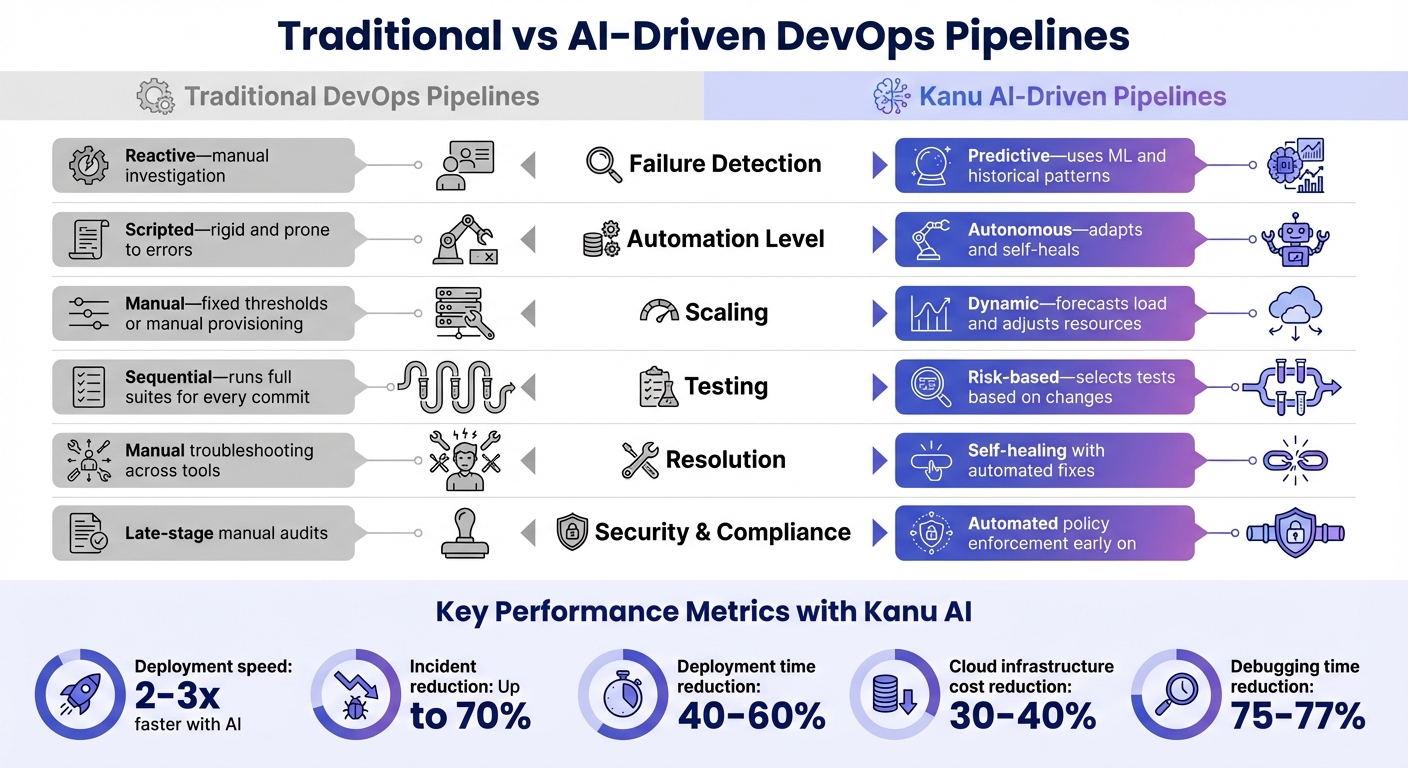
Traditional vs AI-Driven DevOps Pipelines Comparison
The differences between traditional and AI-driven DevOps pipelines go far beyond speed - they represent entirely distinct ways of operating. While traditional pipelines rely on reactive processes and rigid scripting, Kanu AI introduces predictive analytics and self-healing automation that redefine efficiency.
Traditional pipelines often react to issues only after they occur, requiring engineers to sift through GitHub, CI logs, and Kubernetes dashboards to diagnose problems. This process can take hours. In contrast, Kanu AI uses machine learning to analyze historical data, allowing it to predict potential failures even before code is committed. When issues do arise, Kanu consolidates all relevant context - logs, metrics, and code - into a single environment. This eliminates the need for the time-consuming validation process that many teams report wastes over 10 hours each week.
"The bottleneck isn't code generation anymore - it's the validation maze." – Atulpriya Sharma, Sr. Developer Advocate, Testkube
The automation capabilities of Kanu AI also set it apart. Traditional pipelines depend on rigid, rule-based scripts that are prone to breaking over minor syntax errors. On the other hand, Kanu AI employs self-learning models that adapt to changing environments. These models intelligently prioritize tests based on risk, avoiding the inefficiency of running full test suites for every single commit. This approach not only speeds up deployment - by 2 to 3 times faster - but also reduces incidents by as much as 70%.
Scaling further highlights the divide. Traditional pipelines often require manual provisioning or rely on fixed thresholds, which can lead to either overprovisioning or performance bottlenecks. Kanu AI, however, predicts system load and dynamically allocates CI/CD runners. This ensures optimal resource use while maintaining availability. For example, a 2025 case study involving a React 19 microservice showed that Kanu AI reduced lead time for changes by 25% (from 4.8 hours to 3.6 hours) and increased deployment frequency from 2.5 to 3.2 times per day. The AI Triage Agent demonstrated an 85.2% intervention accuracy, and the change failure rate dropped from 8.5% to 5.9%. This case study highlights how dynamic resource allocation can significantly boost pipeline performance.
Comparison Table
| Feature | Traditional DevOps Pipelines | Kanu AI-Driven Pipelines |
|---|---|---|
| Failure Detection | Reactive - manual investigation | Predictive - uses ML and historical patterns |
| Automation Level | Scripted - rigid and prone to errors | Autonomous - adapts and self-heals |
| Scaling | Manual - fixed thresholds or manual provisioning | Dynamic - forecasts load and adjusts resources |
| Testing | Sequential - runs full suites for every commit | Risk-based - selects tests based on changes |
| Resolution | Manual troubleshooting across tools | Self-healing with automated fixes |
| Security & Compliance | Late-stage manual audits | Automated policy enforcement early on |
This side-by-side comparison makes it clear: AI-driven pipelines like Kanu AI not only speed up delivery but also reduce incidents and simplify troubleshooting. Traditional pipelines, with their manual processes and delays, simply can't match the efficiency and confidence that AI brings to modern DevOps workflows.
Conclusion
Addressing bottlenecks in your DevOps pipeline is more than just a matter of speeding up deployments; it's about preserving the benefits of faster coding and maintaining overall delivery efficiency. The strategies discussed - like predictive analytics, automated testing, and intelligent orchestration - show how teams can shift from reactive fixes to proactive problem-solving. This approach not only eliminates delays but also reduces the burden of manual tasks, freeing up time for engineers to focus on innovation.
Kanu AI plays a pivotal role in this transformation by automating tasks that previously required constant human oversight. Instead of manually scaling resources, debugging, or monitoring deployments, the platform takes on these responsibilities autonomously. Organizations adopting AI-driven DevOps tools report impressive results, including a 40%-60% reduction in deployment times and a 30%-40% decrease in cloud infrastructure costs through smarter resource allocation. Additionally, AI-powered root cause analysis has led to a 75%-77% reduction in debugging and investigation time. These efficiencies allow teams to channel their energy into creating and innovating rather than getting bogged down by repetitive troubleshooting.
What sets AI-driven pipelines apart isn't just their speed - it's their reliability. A pipeline that can predict failures, prioritize high-risk changes, and self-heal builds confidence and stability, even as delivery velocity increases. Michael Kwok, Ph.D., VP at IBM Watsonx Code Assistant, captures this shift perfectly:
"AI-native testing... promising to bring speed and quality together, not as things that work against each other, but as built-in parts of the DevOps pipeline".
The future of software delivery lies in the synergy between human expertise and machine precision. Kanu AI doesn't replace engineers - it empowers them. By handling repetitive tasks like log analysis, resource scaling, and validation checks, it enables teams to focus on architecture and innovation. This partnership sets the stage for achieving new levels of stability, speed, and cost efficiency, redefining what’s possible in software delivery.
FAQs
Which pipeline stage is slowing us down the most?
The biggest roadblocks in DevOps pipelines often come down to manual or inefficient processes. Tasks like setting up environments or handling deployments by hand can really slow things down. Add in sluggish build times, poorly optimized testing, and manual deployment steps, and delays become inevitable. Tackling these issues with automation and streamlining workflows can make a huge difference, speeding up pipelines and cutting down on hold-ups.
How can we reduce flaky tests without running the full suite?
To cut down on flaky tests without running the entire test suite, consider leveraging AI-powered tools. These tools can analyze historical test data, spot patterns, and even address flaky tests automatically.
Improving your test design also plays a big role. Avoid relying on hardcoded delays like sleep() calls, use mocks for dependencies, and ensure that your tests remain independent of one another. These steps can significantly reduce instability.
Another key factor is maintaining a stable testing environment. Tools like Docker or Kubernetes can help create consistent conditions for your tests to run smoothly. Additionally, AI can assist in identifying and isolating flaky tests, keeping your pipeline more reliable and efficient.
How do we safely enable self-healing fixes in CI/CD?
To make self-healing fixes in CI/CD pipelines safer, leverage AI-powered tools to identify and address build errors while prioritizing safety. Key practices include:
- Implementing rollback mechanisms: This ensures you can quickly revert changes if something goes wrong.
- Monitoring AI actions: Use observability tools to track and understand what the AI is doing in real time.
- Establishing guardrails: Require tests for all code changes to maintain control and prevent unintended consequences.
By combining these strategies, you can keep automation in check, minimize risks, and ensure your pipelines remain dependable throughout the self-healing process.